Базы данных
Ошибка 1326
В общем-то работало все работало, и тут понадобилось поставить обновление на сервер 1С, вернее обновить 1С с версии 8.2* , на версию 8.3*. После установки консоли 1С, все заработало, все локальные базы добавились, все подключения восстановились, как и на предыдущей платформе, а при попытке подключить SQL базу, физически находящуюся на другом сервере, но внутри домена, выдавалась ошибка 1326, (невозможно установить соединение)… Чего только не перепробовано было, где только не искали решение этой проблемы — все оказывалось тщетно… Причем удаленный сервер исправно пинговался, удаленный SQL сервер спокойно можно было увидеть в консоле локального сервера, а  подключиться сервером 1С к удаленному серверу SQL никак не получалось… Решение оказалось простым — в свойствах Агента сервера 1С:Предприятия 8.3 (x86-64) нужно было прописать вход в систему под учетной записью администратора домена. После чего проблемка устранилась.
подключиться сервером 1С к удаленному серверу SQL никак не получалось… Решение оказалось простым — в свойствах Агента сервера 1С:Предприятия 8.3 (x86-64) нужно было прописать вход в систему под учетной записью администратора домена. После чего проблемка устранилась.
Статейку эту решил написать, потому как ничего вразумительного в интернете не обнаружил, и только совместные усилия четырех человек помогли справиться с трудностью. Мало-ли кому еще может понадобится этот простой совет… 😉
Виды архитектур баз данных
Дрели, бензоинстументы и гидротехника
7. Архитектура реляционной СУБД, составные части РСУБД. Архитектура «файл-сервер», «клиент-сервер», многозвенная архитектура.
Базами данных (БД) называют электронные хранилища информации, доступ к которым осуществляется с помощью одного или нескольких компьютеров. Обычно БД создается для хранения и доступа к данным, содержащим сведения о некоторой предметной области, то есть некоторой области человеческой деятельности или области реального мира. Системы управления базами данных (СУБД) — это программные средства, предназначенные для создания, наполнения, обновления и удаления баз данных. Иными словами, СУБД является интерфейсом между базой данных и прикладными задачами.
Традиционно все СУБД классифицируются в зависимости от модели данных, которая лежит в их основе. Принято выделять иерархическую, сетевую и реляционную модели данных. Иногда к ним добавляют модель данных на основе инвертированных списков. Соответственно говорят об иерархических, сетевых, реляционных СУБД или о СУБД на базе инвертированных списков.
По распространенности и популярности реляционные СУБД сегодня вне конкуренции. Они стали фактическим промышленным стандартом, она была разработана Коддом еще в 1969-70 годах на основе математической теории отношений и опирается на систему понятий, важнейшими из которых являются таблица, отношение, строка, столбец, первичный ключ, внешний ключ.
Реляционная база данных — база данных, основанная на реляционной модели данных. Слово «реляционный» происходит от англ. relation (отношение). Для работы с реляционными БД применяют реляционные СУБД.
Реляционной считается такая база данных, в которой все данные представлены для пользователя в виде прямоугольных таблиц значений данных, и все операции над базой данных сводятся к манипуляциям с таблицами. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных базах данных, является нормализованное n-арное отношение.
В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными базами данных — реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств с некоторыми уточнениями, а второй — на классическом логическом аппарате исчисления предикатов первого порядка. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД – требование целостности сущностей и требование целостности по ссылкам.
В зависимости от расположения отдельных частей СУБД различают локальные и сетевые СУБД.
Все части локальной СУБД размещаются на компьютере пользователя базы данных. Чтобы с одной и той же БД одновременно могло работать несколько пользователей, каждый пользовательский компьютер должен иметь свою копию локальной БД. Существенной проблемой СУБД такого типа является синхронизация копий данных, именно поэтому для решения задач, требующих совместной работы нескольких пользователей, локальные СУБД фактически не используются.
К сетевым относятся файл-серверные, клиент-серверные и распределенные СУБД. Непременным атрибутом этих систем является сеть, обеспечивающая аппаратную связь компьютеров и делающая возможной корпоративную работу множества пользователей с одними и теми же данными.
В файл-серверных СУБД все данные обычно размещаются в одном или нескольких каталогах достаточно мощной машины, специально выделенной для этих целей и постоянно подключенной к сети. Такой компьютер называется файл-сервером — отсюда название СУБД. Безусловным достоинством СУБД этого типа является относительная простота ее создания и обслуживания — фактически все сводится лишь к развертыванию локальной сети и установке на подключенных к ней компьютерах сетевых операционных систем. По счастью, Delphi «умеет» использовать сетевые средства самой популярной в мире ОС — Windows — для создания соответствующих клиентских мест, то есть специального программного обеспечения компьютеров пользователей. Нетрудно заметить, что между локальными и файл-серверными вариантами СУБД нет особых различий, так как в них все части собственно СУБД (кроме данных) находятся на компьютере клиента. По архитектуре они обычно являются однозвенными, но в некоторых случаях могут использовать сервер приложений. Недостатком файл-серверных систем является значительная нагрузка на сеть. Если, например, клиенту нужно отыскать сведения об одной из фирм-партнеров, по сети вначале передается весь файл, содержащий сведения о многих сотнях партнеров, и лишь затем в созданной таким образом локальной копии данных отыскивается нужная запись. Ясно, что при интенсивной работе с данными уже нескольких десятков клиентов пропускная способность сети может оказаться недостаточной, и пользователя будут раздражать значительные задержки в реакции СУБД на его требования. Файл-серверные СУБД могут успешно использоваться в относительно небольших фирмах с количеством клиентских мест до нескольких десятков.
Клиент-серверные (двухзвенные) системы значительно снижают нагрузку на сеть, так как клиент общается с данными через специализированного посредника — сервер базы данных, который размещается на машине с данными. Сервер БД принимает запрос от клиента, отыскивает в данных нужную запись и передает ее клиенту. Таким образом, по сети передается относительно короткий запрос и единственная нужная запись, даже если соответствующий файл с данными содержит сотни тысяч записей. Запрос к серверу формируется на специальном языке структурированных запросов (Structured Query Language, SQL), поэтому часто серверы БД называются SQL-серверами. Серверы БД представляют собой относительно сложные программы, изготавливаемые различными фирмами. К ним относятся, например, Microsoft SQL Server производства корпорации Microsoft, Sybase SQL Server корпорации Sybase, Oracle производства одноименной корпорации1, DB2 корпорации IBM и т. д. SQL-сервером является также и сервер InterBase корпорации Inprise, который поставляется вместе с Delphi в комплектации Enterprise. Клиент-серверные СУБД масштабируются до сотен и тысяч клиентских мест.
Распределенные СУБД могут содержать несколько десятков и сотен серверов БД. Количество клиентских мест в них может достигать десятков и сотен тысяч. Обычно такие СУБД работают на предприятиях государственного масштаба, отдельные подразделения которых разнесены на значительной территории. К таковым, например, относятся подразделения Министерства обороны и Министерства внутренних дел. В распределенных СУБД некоторые серверы могут дублировать друг друга с целью достижения предельно малой вероятности отказов и сбоев, которые могут исказить жизненно важную информацию. Они используют собственные региональные средства связи. Интерес к распределенным СУБД возрос в связи со стремительным развитием Интернета. Опираясь на возможности Интернета, распределенные системы строят не только предприятия государственного масштаба, но и относительно небольшие коммерческие предприятия, обеспечивая своим сотрудникам работу с корпоративными данными на дому и в командировках.
Многозвенная архитектура приложений баз данных вызвана к жизни необходимостью обрабатывать на стороне сервера запросы от большого числа удаленных клиентов. Казалось бы, с этой задачей вполне могут справиться и приложения клиент/сервер. Однако в этом случае при большом числе клиентов вся вычислительная нагрузка ложится на сервер БД, который обладает довольно скудным набором средств для реализации сложной бизнес-логики (хранимые процедуры, триггеры, просмотры и т. д.). И разработчики вынуждены существенно усложнять программный код клиентского ПО, а это крайне нежелательно при наличии большого числа удаленных клиентских компьютеров. Многозвенная архитектура приложений БД призвана исправить перечисленные недостатки. Итак, в рамках этой архитектуры «тонкие» клиенты представляют собой простейшие приложения, обеспечивающие лишь передачу данных, их локальное кэширование, представление средствами пользовательского интерфейса, редактирование и простейшую обработку.
Клиентские приложения обращаются не к серверу БД напрямую, а к специализированному ПО промежуточного слоя. Это может быть и одно звено (простейшая трехзвенная модель) и более сложная структура.
ПО промежуточного слоя называется сервером приложений, принимает запросы клиентов, обрабатывает их в соответствии с запрограммированными правилами бизнес-логики, при необходимости преобразует в форму, удобную для сервера БД и отправляет серверу.
Сервер БД выполняет полученные запросы и отправляет результаты серверу приложений, который адресует данные клиентам.
Создание и заполнение БД на примере СУБД архитектуры «клиент-сервер»
6. Способы и инструменты создания и заполнения БД на примере любой СУБД арх-ры «клиент-сервер»
SQL Server поддерживает реляционную модель данных и выполняет функции создания объектов БД (таблиц, индексов, представлений и т.д.), осуществляет проверку целостности БД и отвечает за безопасность данных в системе.
Доступ пользователя к данным обычно осуществляется с компьютера рабочей станции. При этом создаются соответствующие приложения (например, в средах Visual Basic, Delphi и др.), которые позволяют выполнять операции над данными.
Основные операции, связанные с управлением работой SQL сервера, осуществляются с помощью ряда утилит, входящих в состав системы:
SQL Server Books Online – представляет пользователю справочную поддержку;
SQL Server Query Analyzer – предоставляет пользователю возможность выполнения операторов Transact SQL в БД SQL Server;
SQL Server Service Manager – предоставляет возможность запуска, остановки и временной приостановки работы SQL Server.
Server Enterprise Manager – позволяет выполнять все основные операции администрирования SQL Server.
Инфологическая модель БД
Логическая модель БД
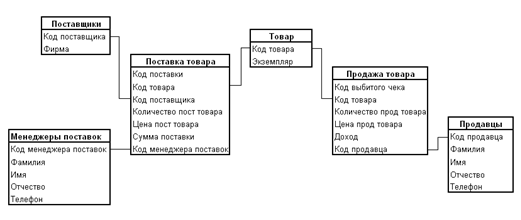
Физическая модель БД

Создадим базу данных «Магазин продуктов»:
create database Magazin_Productov
Затем создадим таблицы:
«Товар»
create table Tovar (codtovara int not null primary key, ekzemplar char(30) not null)
| Атрибуты | Тип | Длина | Ключ | Описание |
| codtovara | int | 4 | primary | Код товара |
| ekzemplar | char | 30 | Наименование товара |
«Поставщики»
create table Postavsiki (codpostavsika int not null primary key, firma char(20) not null)
| Атрибуты | Тип | Длина | Ключ | Описание |
| codpostavsika | int | 4 | primary | Код поставщика |
| firma | char | 20 | Наименование фирмы |
«Менеджеры поставок»
create table Manageri_postavok (cod_meng_postav int not null primary key, familia char(20) not null, imya char(10) not null, otchestvo char(20) not null, telefon int not null)
| Атрибуты | Тип | Длина | Ключ | Описание |
| cod_meng_postav | int | 4 | primary | Код менеджера поставок |
| familia | char | 20 | Фамилия менеджера поставок | |
| imya | char | 10 | Имя менеджера поставок | |
| otchestvo | char | 20 | Отчество менеджера поставок | |
| telefon | int | 4 | Номер телефона менеджера поставок |
Заполним таблицы следующими SQL запросами:
Таблица «Товар»
insert into Tovar values (1, ‘Сыр копченый’)
insert into Tovar values (2, ‘Молоко’)
insert into Tovar values (3, ‘Творог’)
insert into Tovar values (4, ‘Сметана’)
insert into Tovar values (5, ‘Йогурт’)
insert into Tovar values (6, ‘Сыр плавленый’)
insert into Tovar values (7, ‘Кефир’)
insert into Tovar values (8, ‘Ряженка’)
insert into Tovar values (9, ‘Сыр российский’)
insert into Tovar values (10, ‘Снежок’)
Принципы работы блокировок в базе данных
Принципы работы блокировок
Блокировка — это объект, с помощью которого программы показывают зависимость пользователя от ресурса. Программы запрещают другим пользователям выполнять над ресурсами операции, которые негативно влияют на зависимость пользователя, владеющего блокировкой, от этого ресурса. Блокировки управляются внутрисистемными механизмами, они устанавливаются и снимаются в зависимости от действий пользователя.
Блокировки применяются в БД на разных уровнях. Их устанавливают для строк, страниц, ключей, диапазонов ключей, индексов, таблиц или баз данных. SQL Server динамически определяет уровень блокировки для каждого оператора Transact-SQL. Уровень, на котором задается блокировка, может варьироваться для разных объектов в пределах одного запроса. Пользователям не нужно определять уровень блокировки, администраторы также не должны заниматься его настройкой. Каждый экземпляр SQL Server гарантирует, что блокировки, действующие на одном уровне, не нарушат блокировок, установленных на другом уровне.
Существуют несколько видов блокировок: разделяемые, обновления, эксклюзивная, предварительные и блокировки схемы. Вид блокировки показывает уровень зависимости соединения от заблокированного объекта. SQL Server контролирует взаимодействие блокировок разных видов.
|
Lock mode |
Description |
| Разделяемая
Shared (S) |
Используется для операций, не изменяющих данные, например Select |
| Обновления
Update (U) |
Используется на ресурсах, которые могут быть обновлены. Предотвращает коллизии, когда несколько процессов читают, блокируют и потенциально могут изменить ресурсы позднее |
| Экслюзивная
Exclusive (X) |
Используется для действий операций модификации данных. Гарантирует, что несколько процессов не смогут изменять один и тот же ресурс одновременно |
| Предварительная
Intent |
Используется для установки иерархии блокировок. Типы предварительных блокировок: предварительная разделяемая (IS), предварительная эксклюзивная (IX) и предварительная разделяемо-эксклюзивная (SIX) |
| Schema | Используется когда выполняется операция, зависимая от схемы таблиц. Разновидности: модификации схемы (SCH-M) и стабильности схемы (SCH-S) |
| Bulk Update (BU) | Используется в случае операций пакетного обновления данных в таблице и указано предложение TABLOCK |
При разделяемой блокировке, конкурирующие процессы могут читать данные с тех же ресурсов, но не могут изменять эти ресурсы. Освобождение блокировки происходит после того, как инициирующий блокировку процесс прочитал данные ресурса, если только уровень изоляции не установлен равным Repeatable Read или Serializable.
Типичной ситуацией, когда используется блокировка обновления, является ситуация, когда процесс модификации сначала читает ресурс (строку или страницу), устанавливая разделяемую блокировку, а затем изменяет ресурс, что требует изменения типа блокировки на эксклюзивный. Если две транзакции пытаются изменить один и тот же ресурс, то сначала первая транзакция, начавшая операцию модификации меняет тип блокировки на эксклюзивный, а вторая транзакция снимает свою блокировку и ожидает пока первая не завершит операцию обновления ресурса. Это происходит потому, что две транзакции не могут одновременно редактировать один и тот же ресурс. Если транзакция модифицирует ресурс, используя блокировку обновления, то блокировка становится сначала эксклюзивной, а после обновления разделяемой.
Эксклюзивные блокировки предотвращают любой доступ к ресурсу другим процессам.
Предварительная блокировка означает, что процесс желает наложить блокировку (S или X) на один из ресурсов ниже по иерархии ресурсов. Например, предварительная блокировка на уровне таблицы означает, что транзакция будет пытаться накладывать блокировку на страницах или строках данной таблицы. Установка предварительной табличной блокировки может препятствовать установке эксклюзивной блокировки другой транзакции на страницу, принадлежащей данной таблице. Предварительные блокировки разделяются на 3 категории: предварительная эксклюзивная, предварительная разделяемая и предварительная разделяемо- эксклюзивная.
Предварительная разделяемая блокировка означает, что транзакция намерена наложить разделяемую блокировку на некоторое количество (но не на все) объектов ниже по иерархии.
Предварительная эксклюзивная – транзакция намерена изменить некоторое количество ресурсов ниже в иерархии.
Предварительная эксклюзивно-разделяемая, означает, что транзакция намерена прочитать все ресурсы ниже в иерархии и некоторые из них обновить. При этом возможно наложение другой транзакцией IS блокировки. Однако не может быть двух одновременных SIX блокировок на одном объекте.
SCH—M блокировка накладывается в случае выполнения DDL оператора
SCH—S блокировка используется при компиляции запросов. Эти блокировки не запрещают наложения другими транзакциями никаких других блокировок, даже эксклюзивных.
Блокировки пакетного обновления используются в случае пакетной загрузки данных в таблицу или когда используется фраза TABLOCK. Блокировки пакетного обновления позволяют работать транзакциям, загружающим массивы данных в таблицу и предотвращающие доступ другим транзакциям к БД.
В SQL Server предусмотрен алгоритм для обнаружения взаимоблокировок двух соединений. Если экземпляр SQL Server обнаружил взаимоблокировку, то одна из транзакций будет прекращена, что позволит продолжить выполнение другой.
Обработка взаимоблокировок
Взаимоблокировка возникает, когда два или более потоков, конкурирующих за ресурс, становятся взаимозависимыми. Взаимоблокировка возможна не только в РСУБД, но и в любой многопоточной системе, где поток способен захватить один или несколько ресурсов (например, блокировку). Если захватываемый ресурс в настоящее время принадлежит другому потоку, то первый поток ожидает освобождения целевого ресурса его владельцем. В такой ситуации говорят о зависимости ожидающего потока от потока, владеющего некоторым ресурсом.
Если поток-владелец пытается захватить другой ресурс, принадлежащий в настоящее время ожидающему потоку, возникает взаимоблокировка. Ни один поток не может освободить задействованные ресурсы, пока их транзакции не будут зафиксированы или отменены, а этого не случится, поскольку оба потока ожидают освобождения ресурса другим потоком.
Минимизация числа взаимоблокировок
Хотя полностью избежать взаимоблокировок не удается, их число можно существенно уменьшить, чтобы увеличить пропускную способность при обработке транзакций и снизить системные издержки, поскольку меньше транзакций будут подвергаться откату с отменой всей выполненной ими работы. Кроме того, уменьшится число транзакций, повторно переданных приложениями на сервер из-за отката в результате взаимоблокировок.
Чтобы минимизировать число взаимоблокировок, необходимо придерживаться следующих правил:
• не изменять порядок обращения к объектам;
• избегать взаимодействия с пользователем во время транзакции;
• следить, чтобы транзакции были короткими и не выходили за пределы одного пакета;
• использовать низкие уровни изоляции;
• использовать привязанные соединения.
Параллельное управление процессами в базе данных
4. Проблемы параллельного выполнения процессов, модифицирующих БД. Пессимистическое и оптимистическое управление параллельным управлением.
Современные СУБД являются многопользовательскими системами, т.е. допускают параллельную одновременную работу большого количества пользователей. При этом пользователи не должны мешать друг другу.
Если несколько пользователей одновременно обращаются к БД при отсутствии блокировок, возможны ошибки при одновременном использовании в их транзакциях одних и тех же данных. Проблемы с параллельным выполнением бывают следующие:
• потерянные или «скрытые» обновления;
• зависимость от незафиксированных данных («грязное чтение»);
• несогласованный анализ (неповторяемое чтение);
• чтение фантомов.
Потерянные обновления
Потерянные обновления появляются при выборе одной строки двумя или более транзакциями, которые затем обновляют эту строку на основе ее первоначального значения. Ни у одной из транзакций нет сведений о действиях, выполненных другими транзакциями. Поэтому последнее обновление записывается поверх обновлений, сделанных другими транзакциями, что приводит к потере данных.
Зависимость от незафиксированных данных («грязное чтение»)
Зависимость от незафиксированных данных возникает, когда вторая транзакция выбирает строку, которую в это время обновляет первая транзакция. Таким образом, вторая транзакция читает еще не зафиксированные данные, которые могут быть изменены первой транзакцией.
Несогласованный анализ (неповторяемое чтение)
Несогласованным анализом называется ситуация, когда вторая транзакция несколько раз обращается к той же строке, что и первая, однако от раза к разу данные меняются. Несогласованный анализ напоминает неподтвержденную зависимость тем, что первая транзакция изменяет данные, которые читает вторая транзакция. Однако при несогласованном анализе первая транзакция подтверждает изменение этих данных. Кроме того, при несогласованном анализе происходит многократное {двукратное или больше) чтение второй транзакцией одной и той же строки с разными данными (отсюда термин «неповторяемое чтение»).
Чтение фантомов
Так называется ситуация, когда строки из диапазона строк, читаемого во время транзакции, добавляются или удаляются. Первая операция чтения, исполняемая во время транзакции, показывает наличие в прочитанном диапазоне некоторой строки. Если другая транзакция удалит ее, то эта строка не будет обнаружена, когда диапазон будет прочитан в следующий раз. Аналогично, если другая транзакция добавляет в читаемый диапазон строку после первого чтения, эта строка обнаружится только при повторном чтении.
Параллельная работа
Когда множество пользователей одновременно пытаются модифицировать данные в БД, необходимо создать систему управления, которая защитила бы модификации, выполненные одним пользователем, от негативного воздействия модификаций, сделанных другими. Этот процесс называется управлением параллельным выполнением.
Существуют два типа управления параллельным выполнением.
• Пессимистическое управление параллельным выполнением. Система блокировок не разрешает пользователям выполнить модификации, влияющие на других пользователей. Если пользователь выполнил какое-либо действие, в результате которого установлена блокировка, то другим пользователям не удастся выполнять действия, конфликтующие с установленной блокировкой, пока владелец не освободит ее. Этот процесс называется пессимистическим управлением. Он используется главным образом в средах, где высока конкуренция за данные.
• Оптимистическое управление параллельным выполнением. При этом способе управления пользователи не блокируют данные при чтении. Во время обновления система следит, не изменил ли другой пользователь данные после их прочтения. Если другой пользователь модифицировал данные, генерируется ошибка. Как правило, получивший ошибку пользователь, откатывает транзакцию и повторяет операцию снова. Этот способ управления в основном используется в средах с низкой конкуренцией за данные.
SQL Server поддерживает различные механизмы оптимистического и пессимистического управления параллельным выполнением. Пользователю предоставляется право определить тип управления параллельным выполнением, установив уровень изоляции транзакции для соединения и параметры параллельного выполнения для курсоров. Эти атрибуты задают посредством операторов Transact-SQL или через свойства и атрибуты API БД; например ADO, OLE DB и ODBC.
База данных, ограничения, сбои, восстановление…
1. Классификация ограничений целостности.
Ограничение целостности — это некоторое утверждение, которое может быть истинным или ложным в зависимости от состояния базы данных.
Примерами ограничений целостности могут служить следующие утверждения:
Пример 1. Возраст сотрудника не может быть меньше 18 и больше 65 лет.
Пример 2. Каждый сотрудник имеет уникальный табельный номер.
Пример 3. Сотрудник обязан числиться в одном отделе.
Пример 4. Сумма накладной обязана равняться сумме произведений цен
Пример 3 представляет ограничение, реализующее целостность сущности. Пример 4 представляет ограничение, реализующее ссылочную целостность. Во 2 ограничение является достаточно произвольными утверждениями. Любое ограничение целостности является семантическим понятием, т.е. появляется как следствие определенных свойств объектов предметной области и/или их взаимосвязей.
База данных находится в согласованном (целостном) состоянии, если выполнены (удовлетворены) все ограничения целостности, определенные для базы данных.
Для этого необходимо, чтобы СУБД обладала развитыми средствами поддержки ограничений целостности. Если какая-либо СУБД не может отобразить все необходимые ограничения предметной области, то такая база данных хотя и будет находиться в целостном состоянии с точки зрения СУБД, но это состояние не будет правильным с точки зрения пользователя.
Ограничения целостности можно классифицировать несколькими способами:
- По способам реализации.
- По времени проверки.
- По области действия.
Классификация ограничений целостности по способам реализации
Каждая система обладает своими средствами поддержки ограничений целостности. Различают два способа реализации:
- Декларативная поддержка ограничений целостности.
- Процедурная поддержка ограничений целостности.
Декларативная поддержка ограничений целостности заключается в определении ограничений средствами языка определения данных (DDL — Data Definition Language). Обычно средства декларативной поддержки целостности (если они имеются в СУБД) определяют ограничения на значения доменов и атрибутов, целостность сущностей (потенциальные ключи отношений) и ссылочную целостность (целостность внешних ключей). Декларативные ограничения целостности можно использовать при создании и модификации таблиц средствами языка.
Например, следующий оператор создает таблицу PERSON и определяет для нее некоторые ограничения целостности:
CREATE TABLE PERSON
(Pers_Id INTEGER PRIMARY KEY,
Pers_Name CHAR(30) NOT NULL,
Dept_Id REFERENCES DEPART(Dept_Id) ON UPDATE CASCADE ON DELETE CASCADE);
После выполнения оператора для таблицы PERSON будут объявлены следующие ограничения целостности:
- Поле Pers_Id образует потенциальный ключ отношения.
- Поле Pers_Name не может содержать null-значений.
- Поле Dept_Id является внешней ссылкой на родительскую таблицу DEPART, причем, при изменении или удалении строки в родительской таблице каскадно должны быть внесены соответствующие изменения в дочернюю таблицу.
Процедурная поддержка ограничений целостности заключается в использовании триггеров и хранимых процедур.
Не все ограничения целостности можно реализовать декларативно. Примером такого ограничения может служить требование из примера 1, утверждающее, что поле Dept_Kol таблицы DEPART должно содержать количество сотрудников, реально числящихся в подразделении. Для реализации этого ограничения необходимо создать триггер, запускающийся при вставке, модификации и удалении записей в таблице PERSON, который корректно изменяет значение поля Dept_Kol. Например, при вставке в таблицу PERSON новой строки, триггер увеличивает на единицу значение поля Dept_Kol, а при удалении строки — уменьшает. Заметим, что при модификации записей в таблице PERSON могут потребоваться даже более сложные действия. Действительно, модификация записи в таблице PERSON может заключаться в том, что мы переводим сотрудника из одного отдела в другой, меняя значение в поле Dept_Id. При этом необходимо в старом подразделении уменьшить количество сотрудников, а в новом — увеличить.
По времени проверки ограничения делятся на:
- Немедленно проверяемые ограничения.
- Ограничения с отложенной проверкой.
Немедленно проверяемые ограничения проверяются непосредственно в момент выполнения операции, могущей нарушить ограничение. Например, проверка уникальности потенциального ключа проверяется в момент вставки записи в таблицу. Если ограничение нарушается, то такая операция отвергается. Транзакция, внутри которой произошло нарушение немедленно проверяемого утверждения целостности, обычно откатывается.
Ограничения с отложенной проверкой проверяется в момент фиксации транзакции оператором COMMIT WORK. Внутри транзакции ограничение может не выполняться. Если в момент фиксации транзакции обнаруживается нарушение ограничения с отложенной проверкой, то транзакция откатывается. Примером ограничения, которое не может быть проверено немедленно является ограничение из примера 1. Это происходит оттого, что транзакция, заключающаяся во вставке нового сотрудника в таблицу PERSON, состоит не менее чем из двух операций — вставки строки в таблицу PERSON и обновления строки в таблице DEPART. Ограничение, безусловно, неверно после первой операции и становится верным после второй операции.
По области действия ограничения делятся на:
- Ограничения атрибута
- Ограничения кортежа
- Ограничения отношения
- Ограничения базы данных
Ограничение целостности атрибута представляют собой ограничения, накладываемые на допустимые значения атрибута вследствие того, что атрибут основан на каком-либо домене. Ограничение атрибута в точности совпадают с ограничениями соответствующего домена. Отличие ограничений атрибута от ограничений домена в том, что ограничения атрибута проверяются.
Ограничение атрибута является немедленно проверяемым ограничением.
Ограничения целостности кортежа представляют собой ограничения, накладываемые на допустимые значения отдельного кортежа отношения, и не являющиеся ограничением целостности атрибута. Требование, что ограничение относится к отдельному кортежу отношения, означает, что для его проверки не требуется никакой информации о других кортежах отношения. Ограничение наложено на уже имеющееся ограничение либо связывает 2 атрибута одного кортежа.
Ограничения целостности отношения представляют ограничения, накладываемые только на допустимые значения отдельного отношения, и не являющиеся ограничением целостности кортежа. Требование, что ограничение относится к отдельному отношению, означает, что для его проверки не требуется информации о других отношениях.
Ограничение целостности, определяемые наличием функциональных, многозначных зависимостей и зависимостей соединения, являются ограничениями отношения.
Ограничение целостности, определяемое требованием, что некоторая таблица должна быть не пуста, являются ограничениями отношения.
Ограничение отношения может быть как немедленно проверяемым ограничением, так и ограничением с отложенной проверкой.
Ограничения целостности базы данных представляют ограничения, накладываемые на значения двух или более связанных между собой отношений (в том числе отношение может быть связано само с собой).
К моменту проверки ограничения базы данных должны быть проверены ограничения целостности отношений.
Ограничение базы данных может быть как немедленно проверяемым ограничением, так и ограничением с отложенной проверкой.
2. Понятие транзакции. Свойства транзакции. Изоляция транзакций.
Транзакция— это неделимая, с точки зрения воздействия на СУБД, последовательность операций манипулирования данными.
Для пользователя транзакция выполняется по принципу «все или ничего«, т.е. либо транзакция выполняется целиком и переводит базу данных из одного целостного состояния в другое целостное состояние, либо, если по каким-либо причинам, одно из действий транзакции невыполнимо, или произошло какое-либо нарушение работы системы, база данных возвращается в исходное состояние, которое было до начала транзакции (происходит откат транзакции). С этой точки зрения, транзакции важны как в многопользовательских, так и в однопользовательских системах. В однопользовательских системах транзакции — это логические единицы работы, после выполнения которых база данных остается в целостном состоянии. Транзакции являются единицами восстановления данных после сбоев — восстанавливаясь, система ликвидирует следы транзакций, не успевших успешно завершиться в результате программного или аппаратного сбоя. В многопользовательских системах транзакции служат для обеспечения изолированной работы отдельных пользователей — пользователям, одновременно работающим с одной базой данных, кажется, что они работают как бы в однопользовательской системе и не мешают друг другу.
Транзакция— это последовательность операторов манипулирования данными, выполняющаяся как единое целое (все или ничего) и переводящая базу данных из одного целостного состояния в другое целостное состояние.
Транзакция обладает 4мя важными свойствами, известными как свойства АСИД:
- (А) Атомарность. Транзакция выполняется как атомарная операция — либо выполняется вся транзакция целиком, либо она целиком не выполняется.
- (С) Согласованность. Транзакция переводит базу данных из одного согласованного (целостного) состояния в другое согласованное (целостное) состояние. Внутри транзакции согласованность базы данных может нарушаться.
- (И) Изоляция. Транзакции разных пользователей не должны мешать друг другу (например, как если бы они выполнялись строго по очереди).
- (Д) Долговечность. Если транзакция выполнена, то результаты ее работы должны сохраниться в базе данных, даже если в следующий момент произойдет сбой системы.
Транзакция обычно начинается автоматически с момента присоединения пользователя к СУБД и продолжается до тех пор, пока не произойдет одно из следующих событий:
- Подана команда COMMIT WORK (зафиксировать транзакцию).
- Подана команда ROLLBACK WORK (откатить транзакцию).
- Произошло отсоединение пользователя от СУБД.
- Произошел сбой системы.
Свойства АСИД транзакций не всегда выполняются в полном объеме. Особенно это относится к свойству И (изоляция). В идеале, транзакции разных пользователей не должны мешать друг другу, т.е. они должны выполняться так, чтобы у пользователя создавалась иллюзия, что он в системе один. Различается несколько уровней изоляции транзакций. На низшем уровне изоляции транзакции могут реально мешать друг другу, на высшем они полностью изолированы. За большую изоляцию транзакций приходится платить большими накладными расходами системы и замедлением работы. Пользователи или администратор системы могут по своему усмотрению задавать различные уровни всех или отдельных транзакций.
Свойство Д (долговечность) также не является абсолютными свойством, т.к. некоторые системы допускают вложенные транзакции.
Основа восстановления данных после сбоев- архивная копия и журнал изменений базы данных. Во всех случаях основой восстановления является избыточное хранение данных. Эти избыточные данные хранятся в журнале, содержащем последовательность записей об изменении базы данных.
Возможны два основных варианта ведения журнальной информации. В первом варианте для каждой транзакции поддерживается отдельный локальный журнал изменений базы данных этой транзакцией. Кроме того, поддерживается общий журнал изменений базы данных, используемый для восстановления состояния базы данных после мягких и жестких сбоев.
Этот подход позволяет быстро выполнять индивидуальные откаты транзакций, но приводит к дублированию информации в локальных и общем журналах. Поэтому чаще используется второй вариант — поддержание только общего журнала изменений базы данных, который применяется и при выполнении индивидуальных откатов.
Восстановление базы данных может производиться в следующих случаях:
- Индивидуальный откат транзакции. Откат индивидуальной транзакции может быть инициирован либо самой транзакцией путем подачи команды ROLLBACK, либо системой. СУБД может инициировать откат транзакции в случае возникновения какой-либо ошибки в работе транзакции (например, деление на нуль) или если эта транзакция выбрана в качестве жертвы при разрешении тупика.
- Мягкий сбой системы (аварийный отказ программного обеспечения). Мягкий сбой характеризуется утратой оперативной памяти системы. При этом поражаются все выполняющиеся в момент сбоя транзакции, теряется содержимое всех буферов базы данных. Данные, хранящиеся на диске, остаются неповрежденными. Мягкий сбой может произойти, например, в результате аварийного отключения электрического питания или в результате неустранимого сбоя процессора.
- Жесткий сбой системы (аварийный отказ аппаратуры). Жесткий сбой характеризуется повреждением внешних носителей памяти. Жесткий сбой может произойти, например, в результате поломки головок дисковых накопителей.
Во всех трех случаях основой восстановления является избыточность данных, обеспечиваемая журналом транзакций.
Индивидуальный откат транзакции
Для того чтобы можно было выполнить по журналу транзакций индивидуальный откат транзакции, все записи в журнале от данной транзакции связываются в обратный список. Началом списка для не закончившихся транзакций является запись о последнем изменении базы данных, произведенном данной транзакцией. Для закончившихся транзакций (индивидуальные откаты которых уже невозможны) началом списка является запись о конце транзакции, которая обязательно вытолкнута во внешнюю память журнала. Концом списка всегда служит первая запись об изменении базы данных, произведенном данной транзакцией. В каждой записи имеется уникальный системный номер транзакции, чтобы можно было восстановить прямой список записей об изменениях базы данных данной транзакцией.
Индивидуальный откат транзакции выполняется следующим образом:
- Просматривается список записей, сделанных данной транзакцией в журнале транзакций (от последнего изменения к первому изменению).
- Выбирается очередная запись из списка данной транзакции.
- Выполняется противоположная по смыслу операция: вместо операции INSERT выполняется соответствующая операция DELETE, вместо операции DELETE выполняется INSERT, и вместо прямой операции UPDATE обратная операция UPDATE, восстанавливающая предыдущее состояние объекта базы данных.
- Любая из этих обратных операций также журнализируются. Это необходимо делать, потому что во время выполнения индивидуального отката может произойти мягкий сбой, при восстановлении после которого потребуется откатить такую транзакцию, для которой не полностью выполнен индивидуальный откат.
- При успешном завершении отката в журнал заносится запись о конце транзакции.
Восстановление после мягкого сбоя
Несмотря на протокол WAL, после мягкого сбоя не все физические страницы базы данных содержат измененные данные, т.к. не все «грязные» страницы базы данных были вытолкнуты во внешнюю память.
Последний момент, когда гарантированно были вытолкнуты «грязные» страницы — это момент принятия последней контрольной точки.
Восстановление после жесткого сбоя
При жестком сбое база данных на диске нарушается физически. Основой восстановления в этом случае является журнал транзакций и архивная копия базы данных. Архивная копия базы данных должна создаваться периодически, а именно с учетом скорости наполнения журнала транзакций.
Восстановление начинается с обратного копирования базы данных из архивной копии. Затем выполняется просмотр журнала транзакций для выявления всех транзакций, которые закончились успешно до наступления сбоя. (Транзакции, закончившиеся откатом до наступления сбоя, можно не рассматривать). После этого по журналу транзакций в прямом направлении повторяются все успешно законченные транзакции. При этом нет необходимости отката транзакций, прерванных в результате сбоя, т.к. изменения, внесенными этими транзакциями, отсутствуют после восстановления базы данных из резервной копии.
Наиболее плохим случаем является ситуация, когда разрушены физически и база данных, и журнал транзакций. В этом случае единственное, что можно сделать — это восстановить состояние базы данных на момент последнего резервного копирования. Для того чтобы не допустить возникновение такой ситуации, базу данных и журнал транзакций обычно располагают на физически разных дисках, управляемых физически разными контроллерами.
3. Буферизация транзакций и упреждающая запись. Процессы контрольной точки и отложенной записи.
Журнализация изменений тесно связана не только с управлением транзакциями, но и с буферизацией страниц базы данных в оперативной памяти. Буферизация страниц базы данных в оперативной памяти — единственный реальный способ достижения удовлетворительной эффективности СУБД. Записи в журнал буферизуются: при нормальной работе очередная страница выталкивается во внешнюю память журнала только при полном заполнении буфера записями.
Но реальная ситуация является более сложной. Имеются два вида буферов — буфер журнала и буфер страниц оперативной памяти, которые содержат связанную информацию. И те и другие буфера могут выталкиваться во внешнюю память.
Основным принципом согласованной политики выталкивания буфера журнала и буферов страниц базы данных является то, что запись об изменении объекта базы данных должна попадать во внешнюю память журнала раньше, чем измененный объект оказывается во внешней памяти базы данных. Дополнительное условие на выталкивание буферов накладывается тем требованием, что каждая успешно завершившаяся транзакция должна быть реально зафиксирована во внешней памяти.
Имеется 2 причины для периодического выталкивания страниц во внешнюю память – недостаток оперативной памяти и возможность сбоев. Соответствующий протокол журнализации (и управления буферизацией) называется Write Ahead Log (WAL) — «пиши сначала в журнал«, и состоит в том, что если требуется вытолкнуть во внешнюю память измененный объект базы данных, то перед этим нужно гарантировать выталкивание во внешнюю память журнала записи о его изменении. Это означает, что если во внешней памяти базы данных содержится объект, к которому применена некоторая команда модификации, то во внешней памяти журнала транзакций содержится запись об этой операции. Обратное неверно — если во внешней памяти журнала содержится запись о некотором изменении объекта, то во внешней памяти базы данных может и не быть самого измененного объекта.
Какой бы сбой не произошел, система должна быть в состоянии восстановить состояние базы данных, содержащее результаты всех зафиксированных к моменту сбоя транзакций.
Третьим условием выталкивания буферов является ограниченность объемов буферов базы данных и журнала транзакций. Периодически или при наступлении определенного события (например, количество страниц в dirty-списке превысило определенный порог, или количество свободных страниц в буфере уменьшилось и достигло критического значения) система принимает так называемую контрольную точку. Принятие контрольной точки включает выталкивание во внешнюю память содержимого буферов базы данных и специальную физическую запись контрольной точки, которая представляет собой список всех осуществляемых в данный момент транзакций.
Оказывается, что минимальным требованием, гарантирующим возможность восстановления последнего согласованного состояния базы данных, является выталкивание при фиксации транзакции во внешнюю память журнала всех записей об изменении базы данных этой транзакцией. При этом последней записью в журнал, производимой от имени данной транзакции, является специальная запись о конце этой транзакции.
Программа отложенной записи (Lazy Writer)
Программа отложенной записи в SQL Server 2000 и SQL Server 7.0 пытается определить расположение до 16-ти уникальных страниц нуждающихся в перемещении для возврата их в число свободных страниц. Если счётчик ссылок страницы дойдёт до нуля, она может быть возвращена в качестве свободной. Если страница отмечена как «грязная», её записи журнала и страницы данных будут сброшены на диск. Таким образом, программа отложенной записи может единовременно сбросить на диск 16*16 страниц. Это будет достаточно эффективно, потому что многие из этих страниц останутся в буферном пуле SQL Server, но будут находиться после этого в состоянии — «свободна».